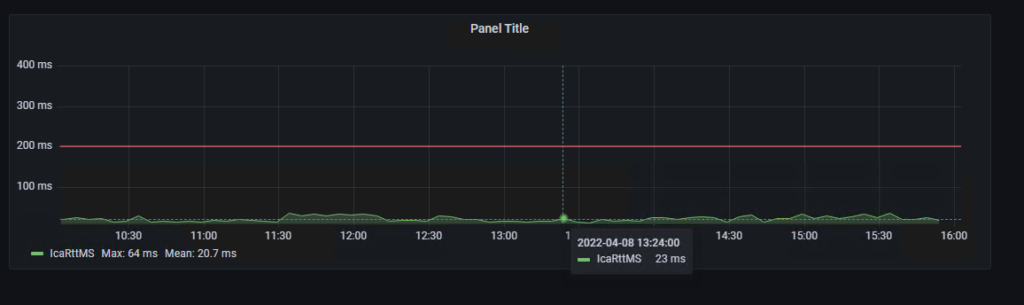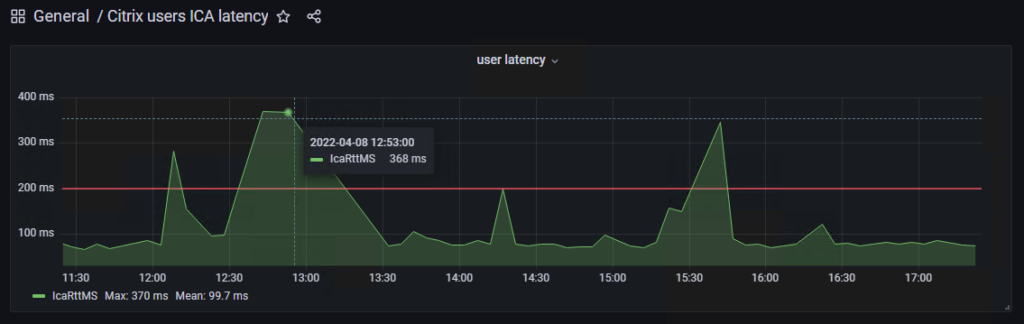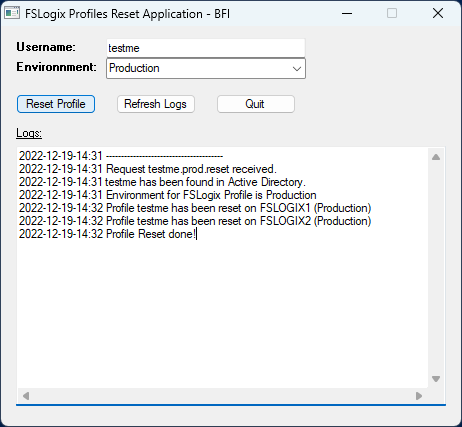
I have developped a small app to replace the “Reset Profile” button in Director, that Service Desk agents love so much, to work with FSLogix.
The application is a client/server model so the application doesn’t require admin rights to work. With ACLs on the executable only Service Desk and Admins can run it. The application can be published in the Start Menu for easy access.
The application will do the following:
- Check periodically if a reset request has been logged by a service desk agent
- Check if the user exists in Active Directory
- Check if the environment is Production or Test
- Check if the profile is locked
- Reset (rename) the profile in each location (SMB shares)
The service desk agent type in the username (sam account name), click on “Reset Profile” and then click on “Refresh Logs” to see the result of the action. If the username doesn’t exist in AD, or if the profile is locked, this will appear in the application interface.
The application works with a frontend VB script compiled with AutoIT, and a PowerShell script running on a management server with a service account with rights to rename folders in the SMB shares. The app has been designed to work with Cloud Cache and multiple file shares.
The frontend application send a text file containing the username information to a share on the management server. The PowerShell script will check for request files in the local share, process the request, and delete the request file.
The VB script in AutoIT is the following:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 |
#Region ;**** Directives created by AutoIt3Wrapper_GUI **** #AutoIt3Wrapper_Res_Comment=For the BFI by Olivier Marchetta #AutoIt3Wrapper_Res_Description=Reset FS Logix Profiles with Cloud Cache technology #AutoIt3Wrapper_Res_File_Add=C:\fslogix-profiles-reset\app\2JRCXKBo_400x400.jpg #EndRegion ;**** Directives created by AutoIt3Wrapper_GUI **** #include <FileConstants.au3> #include <MsgBoxConstants.au3> #include <WinAPIFiles.au3> #include <GUIConstantsEx.au3> #include <WindowsConstants.au3> #include <GuiEdit.au3> #include <ScrollBarsConstants.au3> ; Create a GUI with various controls. Local $hGUI = GUICreate("FSLogix Profiles Reset Application - BFI", 460, 400) ; Logs $logfile = FileRead("\\ManagementServer\reset-logs\fslogix-reset.log") Local $logs = GUICtrlCreateEdit($logfile, 15, 120, 430, 260) GUICtrlSetState($logs, $GUI_FOCUS) Local $label0 = GUICtrlCreateLabel("Logs:", 15, 100, 200, 20) GUICtrlSetFont($label0, Default, 0, 4) ; Logo ;Local $logo = GUICtrlCreatePic("2JRCXKBo_400x400.jpg", 8, 8,120, 130) ; username Local $label1 = GUICtrlCreateLabel("Username:", 15, 14, 60, 20) GUICtrlSetFont($label1, Default, 600) Local $usernameinput = GUICtrlCreateInput("", 105, 12, 200, 20) ; environnment Local $label2 = GUICtrlCreateLabel("Environnment:", 15, 34, 80, 20) GUICtrlSetFont($label2, Default, 600) Local $envselect = GUICtrlCreateCombo("Production", 105, 32, 200, 20) GUICtrlSetData($envselect, "Test", "Production") ; Buttons Local $idBtn1 = GUICtrlCreateButton("Reset Profile", 15, 68, 80, 20) Local $idBtn2 = GUICtrlCreateButton("Refresh Logs", 115, 68, 80, 20) Local $idBtn3 = GUICtrlCreateButton("Quit", 215, 68, 80, 20) GUISetState(@SW_SHOW) _GUICtrlEdit_Scroll ( $logs, $SB_SCROLLCARET ) ; Loop until the user exits. While 1 Switch GUIGetMsg() Case $GUI_EVENT_CLOSE ExitLoop Case $idBtn1 SendRequest() Case $idBtn2 Local $logs_updated = FileRead("\\ManagementServr\reset-logs\fslogix-reset.log") GUICtrlSetData($logs, $logs_updated) _GUICtrlEdit_Scroll ( $logs, $SB_SCROLLCARET ) Case $idBtn3 ExitLoop EndSwitch WEnd Func SendRequest() $sam = GUICtrlRead($usernameinput) $request = "\\ManagementServer\fslogix-profiles-reset\requests\" & $sam & ".prod.reset" $file = FileOpen($request,1) FileClose ($file) MsgBox($MB_SYSTEMMODAL, "Title", "Reset request has been sent to the management server.") EndFunc |
And the PowerShell script running on the management server:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 |
# Rename FSLogix profile fodler to reset the user profile with a Cloud Cache configruation # including 2 CC repositories # and 2 environments - Test and Prod Import-Module ActiveDirectory # Log file $logfile = "C:\fslogix-profiles-reset\logs\fslogix-reset.log" # Infinite Loop For (;;) { # Get request file $request = Get-ChildItem -Path C:\fslogix-profiles-reset\requests\*.reset | Select-Object Name -First 1 # If request found then proceed If ($request) { # Get-Date short $date = Get-Date -Format "yyyy-MM-dd" # Get-Date with time for logging $datelog = Get-Date -Format "yyyy-MM-dd-HH:mm" "$datelog ---------------------------------------" | Out-File $logfile -Append # Log the request found "$datelog Request $request received." | Out-File $logfile -Append # Get request information $input = $request.Name # Get user sam and SID $pos = $input.IndexOf(".") $sam = $input.Substring(0, $pos) $sid = Get-Aduser $sam $sid = $sid.SID # If no SID do nothing, else proceed with profile reset If (!$sid) { "$datelog User $sam not found in Active Directory." | Out-File $logfile -Append "$datelog No further actions will be processed." | Out-File $logfile -Append } Else { "$datelog User $sam has been found in Active Directory." | Out-File $logfile -Append # Get environment (prod or test) If ($input -like '*.prod.*') { $environment = "prod" "$datelog Environment for FSLogix Profile is Production" | Out-File $logfile -Append } If ($input -like '*.test.*') { $environment = "test" "$datelog Environment for FSLogx Profile is Test" | Out-File $logfile -Append } # Cloud Cache Profile Locations $CC1ProdProfileCurrent = "\\FILESERVER1\Profiles\Prod" + "\" + $sam + "_" + $sid $CC2ProdProfileCurrent = "\\FILESERVER2\Profiles\Prod" + "\" + $sam + "_" + $sid $CC1TestProfileCurrent = "\\FILESERVER1\Profiles\Test" + "\" + $sam + "_" + $sid $CC2TestProfileCurrent = "\\FILESERVER2\Profiles\Test" + "\" + $sam + "_" + $sid # .old + date renaming $CC1ProdProfileRenamed = "\\FILESERVER1\Profiles\Prod" + "\" + $sam + ".old." + $date $CC2ProdProfileRenamed = "\\FILESERVER2\Profiles\Prod" + "\" + $sam + ".old." + $date $CC1TestProfileRenamed = "\\FILESERVER1\Profiles\Test" + "\" + $sam + ".old." + $date $CC2TestProfileRenamed = "\\FILESERVER2\Profiles\Test" + "\" + $sam + ".old." + $date # Work variables $jobdone = 0 $CC1done = 0 $CC2done = 0 # Check if profile is locked If ($environment -eq "prod") { $CC1ProdProfileLock = $CC1ProdProfileCurrent + "\*.lock" $CC2ProdProfileLock = $CC2ProdProfileCurrent + "\*.lock" If (Test-Path $CC1ProdProfileLock){ "$datelog User profile is locked on GRAVITY1" | Out-File $logfile -Append $jobdone = 1 } If (Test-Path $CC2ProdProfileLock){ "$datelog User profile is locked on GRAVITY3" | Out-File $logfile -Append $jobdone = 1 } If ($jobdone -eq 1){ "$datelog User profile is locked. Reset cannot be performed" | Out-File $logfile -Append } } # Reset profile (rename profile folder) While ($jobdone -eq 0) { If ($environment -eq "prod") { # Rename CC1 Prod If ((Test-Path $CC1ProdProfileCurrent) -and !(Test-Path $CC1ProdProfileRenamed)) { Rename-Item $CC1ProdProfileCurrent $CC1ProdProfileRenamed } Else { $CC1done = 1 "$datelog Profile $sam has been reset on GRAVTY1 (Production)" | Out-File $logfile -Append } # Rename CC2 Prod If ((Test-Path $CC2ProdProfileCurrent) -and !(Test-Path $CC2ProdProfileRenamed)) { Rename-Item $CC2ProdProfileCurrent $CC2ProdProfileRenamed } Else { $CC2done = 1 "$datelog Profile $sam has been reset on GRAVTY3 (Production)" | Out-File $logfile -Append } } If ($environment -eq "test") { # Rename CC1 Test If ((Test-Path $CC1TestProfileCurrent) -and !(Test-Path $CC1TestProfileRenamed)) { Rename-Item $CC1TestProfileCurrent $CC1TestProfileRenamed } Else { $CC1done = 1 "$datelog Profile $sam has been reset on GRAVTY1 (Test)" | Out-File $logfile -Append } # Rename CC2 Test If ((Test-Path $CC2TestProfileCurrent) -and !(Test-Path $CC2TestProfileRenamed)) { Rename-Item $CC2TestProfileCurrent $CC2TestProfileRenamed } Else { $CC2done = 1 "$datelog Profile $sam has been reset on GRAVTY3 (Test)" | Out-File $logfile -Append } } If ($CC1done -eq 1 -and $CC2done -eq 1) { $jobdone = 1 "$datelog Profile Reset done!" | Out-File $logfile -Append } # 1 second cooldown Start-Sleep 1 } # Remove user from the exclusion group #If ($jobdone -eq 1) { #Remove-ADGroupMember -Identity "FSLogix Profile Exclude List" -Members $sam -Confirm False #"$datelog $sam has been removed from the exclusion group" | Out-File $logfile -Append # } } # Delete the request file Get-ChildItem -Path C:\fslogix-profiles-reset\requests\*.reset | Remove-Item -Force # Clear some variables Clear-Variable sid Clear-Variable sam Clear-Variable request} # End of the Inifite Loop Start-Sleep 1 } |
Just compile the first script, that’s your app.
Run the PowerShell on the management server.
Create a local share on the Management server in:
|
1 |
C:\fslogix-profiles-reset\requests |
I run the compiled app from:
|
1 |
C:\fslogix-profiles-reset\app |
And the logs are read from:
|
1 |
C:\fslogix-profiles-reset\logs |
Update the server names to match your environment. Enjoy!