

When a UPM to FSLogix profile big-bang migration ends up in a total train wreck.
Storyline: I have used a migration script, modified from the David Ott script, which you can find on this website, and it works very well. But the script will not detect damaged or bad UPM profiles, and that’s when the project can go wrong. It is like watching a rocket launch, so far so good, 75 users ok, 150 users ok, 300 users ok, monitors are all ok, green lights, 400 users… And suddenly all the Citrix Desktop servers begin to freeze and no one can work. All dashboards blinking in red. So what happened? Let’s investigate the crash site and see what led the rocket to bend and explode in mid-air….
Once upon a time…
First, the migration takes place on Windows Server 2016 with FSLogix 2201 (not HF1) and Cloud Cache. This operating system has a very weak Start Menu, using a deprecated technology to manage the shortcuts and the “tiles”. It use a database, and always was before this deployment a source of numerous issues. The Start Menu would freeze or not refresh the icons at logon. With UPM, Citrix has deployed several fixes for this, to use in combination with different registry keys like the “ImmersiveShell\StateStore” “Reset Cache” key, or clean the UFH/SHC key (also a deprecated feature! But still impacting Windows 2016). If I remember well Citrix fixed the issue once for all with the 7.15 CU3 release, but would only work with a clean install, using a VDA clean-up tool, and a proper re-install of the VDA. But it seems that in our user base, many profiles were still “broken” and had a broken start menu…. Something that FSlogix was not aware of?
Pre-Migration test and early adopters… all is fine!
So we migrated 75 users initially, using the migration script, from UPM to FSLogix. We experienced a couple of black screens, but first it was mainly due to the infrastructure – using a very slow file server hosting many other roles and sometimes due to the Start Menu cache or the UFH/SHC key that would need a good clean-up. And we tested FSLogix inside out, thoroughly, for a full five months. We migrated the profiles to brand new file servers, dedicated, with enough resources, and using a large 8 TB disk formatted in ReFS. The logs showed that, in terms of infrastructure, the disks would be access and mapped in less than 100ms before the shell would kick in. Logon were super-fast. No reliability issues. Everyone was confident, this migration will be a success, we kept the champagne in the freezer, it was already a done deal and just waited for the celebration day…..
Houston, we have a problem…
Before the big bang, I migrated another 25 users for 3 to 4 days, and we didn’t notice anything except one, a single one, server freeze. This is not uncommon, and in the morning checks the service desk and Ops team would just investigate the issue quickly, RDP to the server, if frozen or slow, put it in maintenance mode, restart it and if it is solved, then the ticket is closed and sent to the archives. I have been made aware of this freeze, but the issue was not reported as critical yet, so I didn’t investigate it myself. We had 49 other active servers without any issues on 100 FSLogix profiles and 400 UPM profiles. So I began the big-bang migration.
The rate was done at 50 users per night, and we would monitor the logons in the morning and throughout the day. We quickly raised the FSLogix users from jsut 100 to 300. So far no issues. But when we reached 350 users, the service desk started to report black screens and slow logons. I quickly pushed the Start Menu reset cache reg keys, as I know this could fix the problem, and migrated another 50 users that same day to reach 400 FSlogix users.
That’s when hell broke loose, and all started to flinch. The next day, the service desk reported that a group of users, around 10, would have black screens at logon, but many more would report a frozen server.
There was a bit of a reaction time here from me, still very focused on finishing the migration. The target is 600 profiles. I would just ask the SD/Ops to put the servers in maintenance mode, and add them to the restart queue for the night, while I was adding more users to the migration – big mistake.
The day after we had no options but to realise that 7-8 servers would randomly freeze in the morning, with black screens for over 100 users. That’s when I moved my focus to the issue.
Looking into the FSLogix log files first, to see nothing but no errors and a fast disk access an mapping, stlil under 100ms, before the shell would kick in. Citrix Director would report the logon time as 30 seconds, when the users would have a black screen for 10 minutes or more!
At this stage I didn’t know if it was the server that could not cope with the load of FSLogix profiles over UPM profiles, or of it was a user issue. My second mistake was to make a too fast conclusion that it was the server itself and not the profiles causing the issue. Reviewing KBs and other community posts, I realise that maybe FSLogix verson 2201 without the HotFix1 was the problem. Maybe the AppReadiness service was the issue even If I knew that it never caused any issues before, but now maybe under the load of so many profiles on the server? Another thing is that we knew that the black screens would last longer than 5 minutes, so I was quite sure that the AppReadiness service was not the cause of the black screen, but I would nevertheless do something about it too.
So I opened the Gold Image, and made a couple of integrity check, upgraded FSLogix to 2201 HF1, added some Windows Updates, reviewed the Start Menu policies and clean-up scripts (removing them), changed the AppReadiness service startup to automatic (as we have plenty of memory, I do not care about it staying up all day). And published the image to some servers…. without any improvement.
This mistake made me lose a crucial time, I didn’t drill down right on the issue so the users started to complain about the project, and the SD team joined them, the management would now ask to take the project to a halt and even reverse some profiles back to UPM. I had to intervene and ask everyone to keep their blood cold, and provide more inputs so we have a better chance to at least mitigate the issue.
Looking in details to the servers logs, Applications logs, I finally found the cause. A TileDataLayer DB file, in the user AppData Local folder, would be locked or corrupt and this would cause the Start Menu on the server to crash when trying to open the file in loop, impacting everyone else on the server (Start Menu would fail for all users on that server), and would expand the issue to the taskbar after a while, and then block all applications UI, eventually…
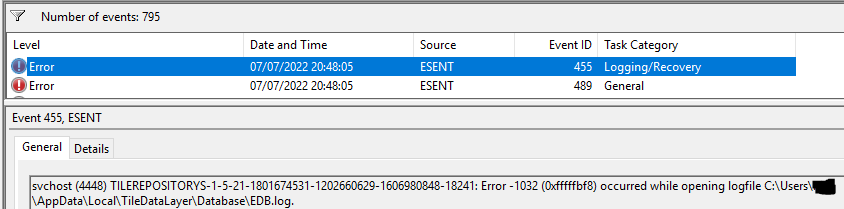
I was able to isolate one user, log him/her off, and ask the user to login again. I could then see that the issue would happen instantly for the same user when the shell would be started. And freezing the entire server. I then locked the account to open the FSLogix container on the fileserver, navigate to the folder and delete all the DB files inside the profile disk.
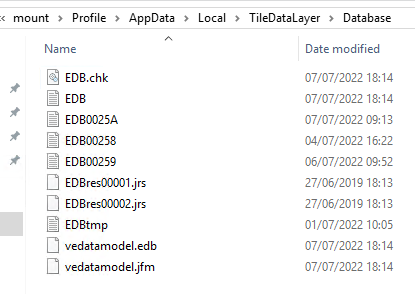
After this, the user would not experience the issue at logon. Using a quick and dirty PowerShell script, I was able to scan all Application logs on each server and locate the issue. Giving me a sort of dashboard nearly in real time to see who would login with a bad profile and impact a server.
I could then locate the user and try to mitigate the issue. But the damage is already done, so the best option is to let the day end, with a couple of very slow, near-dead servers, but make a list of the bad profiles and fix them at night…..
Conclusion
What could have prevented the disaster? On such limited resources as me being the sole consultant doing the migration, with a limited service desk resource, I must have used a double safety net and not attempt such a fast paced migration. The long testing phase with only 75 users, followed by a very fast paced migration of 50 users per day to reach a large target of 600 users is I think the issue here. It was too slow at the beginning, and too fast at the end. A recipe for a crash to happen at the next turn.
I didn’t take the steps back to look art the big picture on the project timeline and failed to use measures of safety. In the end, even if 40 out of 50 servers are still working everyday without being impacted, the project is still considered as a massive failure. The user experience was degraded, substantially, and the negative atmosphere has spread on the user’s IT slack channel, and on the Service Desk team, to finally spread the panic to all IT staff. Technical actions were taken with a short lag and delay, errors were made, followed by better focused actions, but that was too late to contain the bad image and bad user experience for this technology. And it is now just water under the bridge to have the users returning to peace. Lesson learned?
very nice writeup! you also had some bad luck that those users with broken profiles showed up so late in the process.